The website redesign continues! Next up is the ‘About Us’ section. I find it more difficult to do sometimes, because our users don’t use the About section nearly as much, so don’t always have much of an opinion about it. Although it goes against my usual inclination, I decided to go ahead with only minimal feedback. Continue reading “About Us Redesign & Reorganization”
Category: Project work
includes School Work
Making Your Website Accessible Part 3: Content WCAG Compliance
This is actually a repost of my guest post on the ACRL TechConnect Blog. Continue reading “Making Your Website Accessible Part 3: Content WCAG Compliance”
Redesigning the Digital Commons Page
Recently, our team has been assisting with a new initiative to make sure documents sent in to our institutional repository (IR) are accessible. I won’t go into much detail, but since this new initiative was being launched, it was proposed to have the digital commons (our IR) page redesigned for the launch.
Old Page
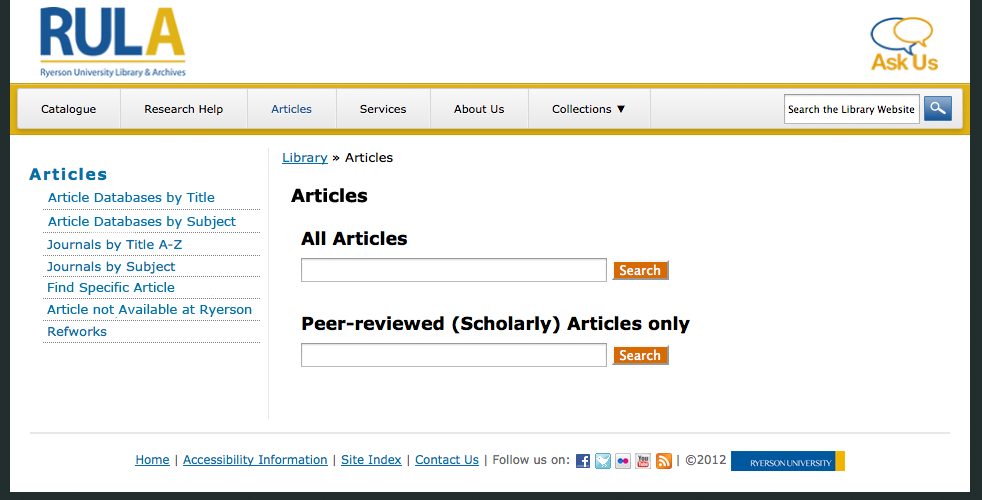
The old page was really just a lot of text, and too much of it. I’m also not sure how long it had been since anyone had revised it. The biggest problem was that it was difficult to find what you wanted, especially how or where to submit a document.

Mockups
So the first mockup was actually given to me by the group working on the IR project. While a vast improvement over the original page, I was not a fan of the quadrant look. I’m probably biased because it was overused at my last work place, but regardless, I thought I could do better.

One thing that didn’t make sense to me was why you would have a link to a search page instead of just building in a search on the page (same with the news). While a search box was thought of, I’m not sure how it would’ve worked into the square design. I was actually working on the Articles redesign around the same time, so I ended up using some of the ideas I had floating around in my head already.

The colours I used were based on the first mockup, which were in turn based on the IR site’s colours.
Redesigned Page
The redesigned page came out pretty much exactly as the mockup. However, the project members called me the day after to tell me that the green shows as a very ugly yellow if the screen or projector is not properly calibrated. So, I ended up changing the colours to our library’s colours.

Most of the text that was on the original page is now on the About page linked from this landing page. I think it’s a huge improvement, so hopefully it helps to encourage more of our users to submit things to our IR.
Implemeting an Issue Tracker (Redmine)
For more than half a year now, I’ve been trying to get an issue tracker fully implemented for our IT team within the library. I admit that I’m still working on it. Getting the system up and running was easy enough, but trying to work it into people’s workflow isn’t so easy.
Choosing the Issue Tracker
There are a lot of issue trackers out there, but we are a small team and I wanted the issue tracker running easily and quickly. It’s not something I wanted to spend a lot of time getting up and running, because we had a lot of other projects happening.
Other requirements included:
- support multiple projects
- non-members being able to report issues
- support email issue management (either built-in or plugin)
- low to no cost
preferable
- support CAS or LDAP login (either built-in or plugin)
- documentation area and/or wiki
- code repository integration
- open source
I asked around a little bit, and these were the recommendations I got:
- Asana: 2
- FogBugz: 1 Against: 1
- Footprints: – Against: 1
- Github: 2
- JIRA: – Against: 2
- Pivotal Tracker: – Against: 1
- Redmine: 5
- Request Tracker: 1 Against: 1
- SupportPress (for WordPress): 1
- Trac: 3 Against: 1
Trac and Redmine seemed to be the two forerunners. My problem with Trac was that it didn’t have clear project organization, and no one could confirm that the email issue management plugin worked.
Installation & Setup
Our system administrator took a couple of (not full) days to get it installed and going, and following the instructions were apparently fairly easy. Then it took me maybe half a day to set up all the projects and users with the settings I wanted. The e-mail creation also worked well out of the box. We just had to make sure we had the right settings for what we wanted.
Staff Issue Creation & Management
In order to make it so that staff can file issues without ever having to see Redmine, I created a form in our Intranet (webform module in Drupal). The form had most of the standard fields:
- Name: automatically filled in with username
- E-mail: also automatically filled in
- Related to: options which were essentially the project names
- Need: options equivalent to tracker e.g. Support, Bug Fix, etc.
- Priority: options equivalent to priority
- Summary: email subject line, which then turns into issue name
- Description: issue details
Once it’s submitted, a copy is sent to our team’s email. Through a cron job (every 5 minutes or so), the email is picked up, and filed.
If the user already exists in the system, Redmine will use the email from the user account to match it to the user, they will automatically become the ‘reporter’ of the issue, and get a copy.
If the user does not exist in the system, Redmine will say that ‘Anonymous’ reported it. This will always happen the first time someone reports an issue as I did not add everyone on staff to the system. So, the first time this happens, I then add the user to the system, and add them as a watcher to the issue.
The one issue I ran into was that I forgot you have to set both the email plugin and each project to accept issues from anonymous users. Simple carelessness really.
Getting Staff to Change their Workflow
I think the hardest part with implementing any issue tracker is getting staff to use it. Within the team, it hasn’t been too difficult. We have a small team and the developers in particular have no problems using it. The only problem I sometimes have is making sure they close issues when they’re done with them.
But even within the team, sometimes it can be difficult to get people to report issues using Redmine. While our manager wanted us to start using it just for the website, it has worked well enough, so we’re strategizing how to get the rest of the staff using it now.
We’ve concluded that it kind of needs to be an all or nothing. So we’ve decided that all non-urgent issues should be done through the intranet form regardless of the project, and that should people email us, we’re going to be emailing them back to submit it through the form.
For any urgent issues and for immediate support, they can still call us. After all, trying to walk someone through editing something on our website or intranet is much easier by phone anyway.
Before we start enforcing it, we’ll be introducing this workflow to staff through various committee meetings in part to gather feedback.
So… we’ll see how it goes.
Revised Articles Section & New Landing Page: Using a Card Sort to Clean Up
As part of the ongoing effort to improve the website, I have been redesigning the website one section at a time. Earlier in the term, I did the Research Help section. In the last couple of weeks (that’s right, only about 2-3 weeks!), I worked on getting the ‘Articles’ section cleaned up with a new landing page.

Card Sort to Clean Up
 I knew that I wouldn’t have time to do a proper card sort study, but I decided to do a card sort with the web committee. We have enough people that I divided the committee up into two groups and gave them sticky notes with the names of the existing pages.
I knew that I wouldn’t have time to do a proper card sort study, but I decided to do a card sort with the web committee. We have enough people that I divided the committee up into two groups and gave them sticky notes with the names of the existing pages.
The sticky notes consistent all the local navigation links from the left side of the existing page and the second level links you see in the expanded part of the ‘More’ menu here (right). Then, I gave the usual instructions for a silent open card sort (no talking, group as you see fit).
While the purpose of a card sort is not to help clean up a section, it really got staff to see what fit in the Articles section and what didn’t. A lot of the pages were also deemed no longer relevant.
As a group, we made decisions on what to remove, and what to move and where. Quite a lot of the content was moved to either our subject research guides or our FAQ system.
There were one or two pages that we couldn’t decide what to do with, so for the time being they’ve been left where they are for now (e.g. RefWorks page is still in the ‘Articles’ menu though not linked on the landing page).
Mockups
With the pages that were left, I created a few mockups.
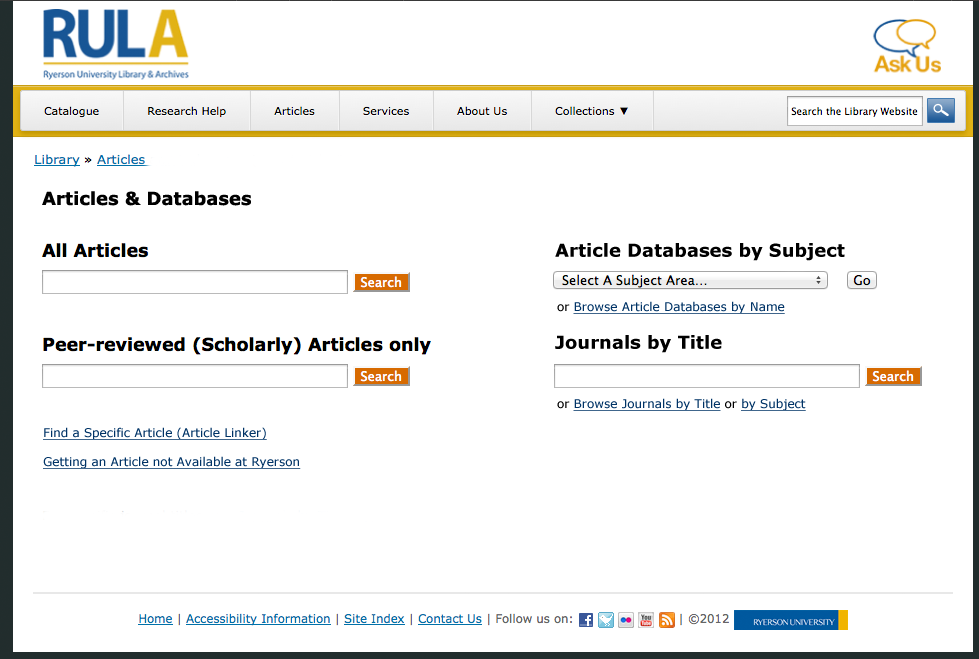
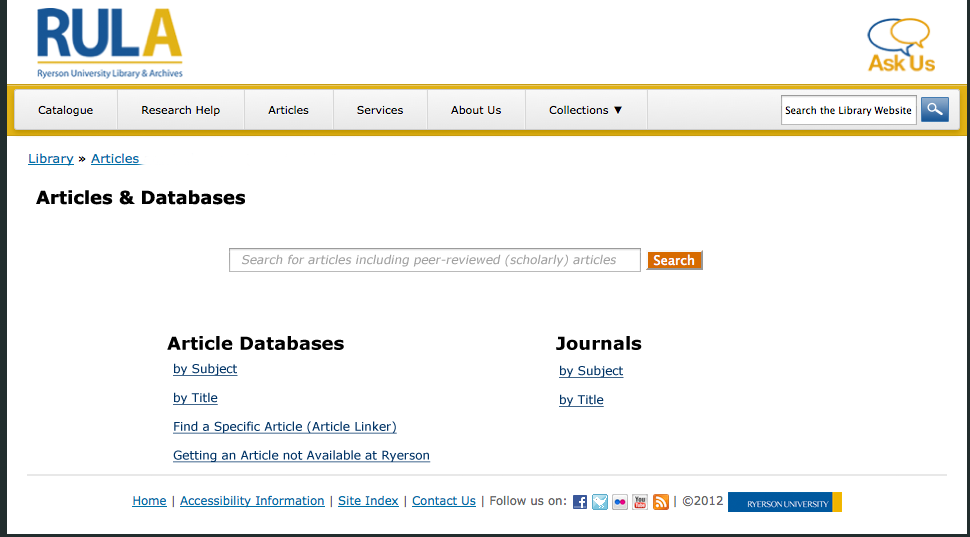
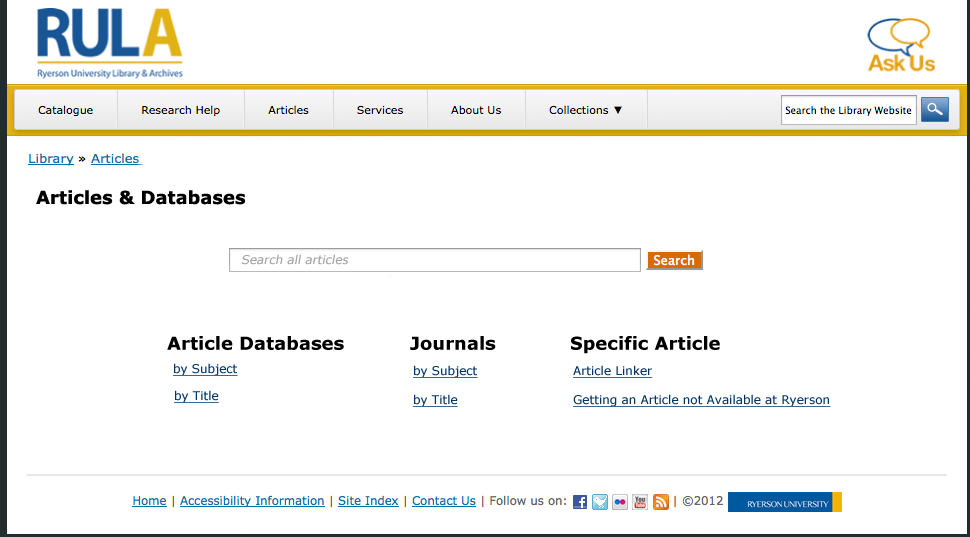
The web committee met again to discuss the mockups. I already had my heart set on either #2 or #3, because the whole idea is that it’s simple and clear. Having only one search bar with just a few links give users focus on what they’re looking for. Different people had different preferences on mockups, but with some discussion, the group settled on mockup #3 with a few revisions.
Staff Feedback
As with the research help page, I posted the revised Articles mockup in the staff room to give everyone a chance to provide feedback. This time, I didn’t get any feedback that resulted in any changes, so the final page is the same as the revised version.
New Page
Even though I’m on vacation, I wanted to get the new page up before the next term, so the new ‘Articles’ landing page went up this week.
